The Self-Improving Loop: a 300-agent swarm on Kimi K2.6, verified by Opus 4.8
本文介绍了Kimi K2.6模型驱动的300代理并行群集系统,通过规范、分解、执行、验证、存储技能和循环反馈,实现每次运行后系统级自我进化,大幅降低后续成本并提升输出质量。
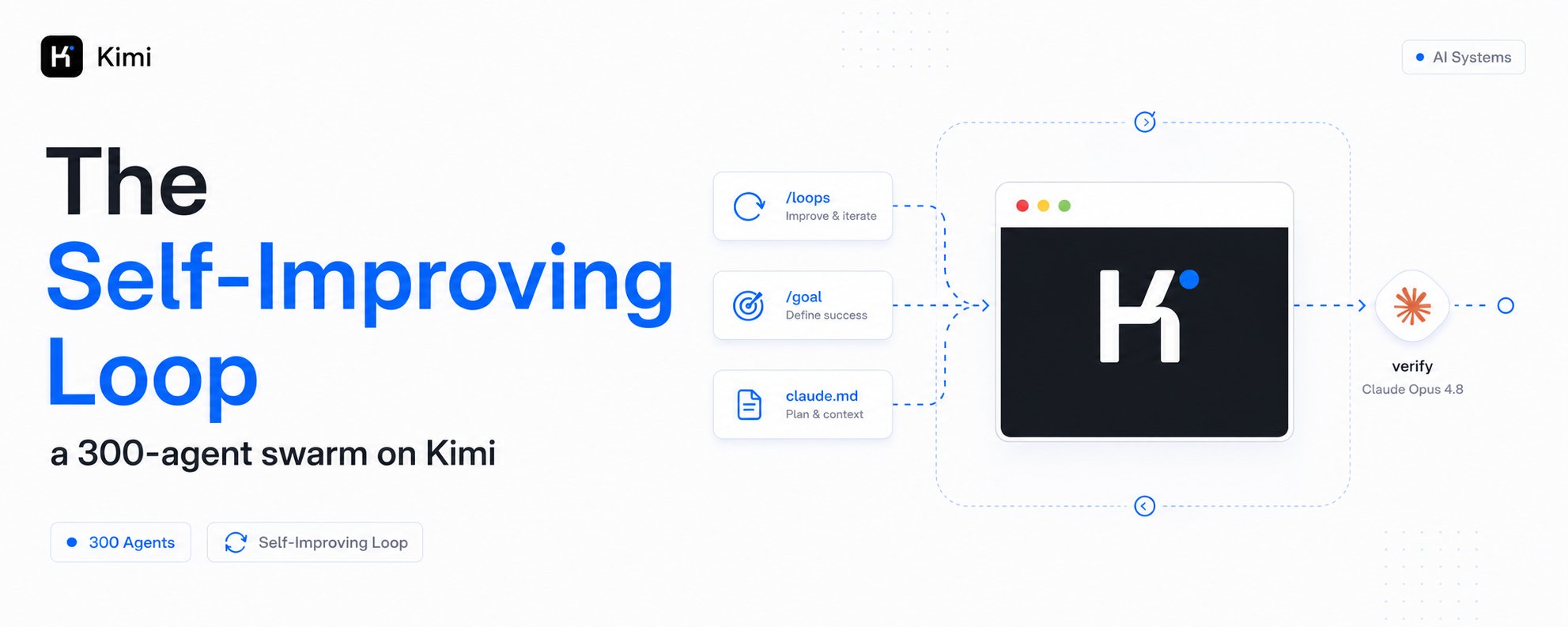
A free open-source model is running 300 parallel agents across 4,000 coordinated steps from a single prompt, and it scores higher on real research tasks than models you pay 5x more for.
一个免费的开源模型,从单个提示开始运行300个并行代理,跨越4000个协调步骤,它在真实研究任务上的得分比你要支付5倍价格的模型还要高。
Most people have never opened it.
大多数人从未打开过它。
They open Kimi, type a question, get an answer, close the tab. That’s the chatbox. It works. It’s also about 10% of what the product does.
他们打开Kimi,输入一个问题,得到答案,关闭标签页。这就是聊天框。它有用。但这只是该产品功能的10%左右。
Here’s the part most people skip:
这是大多数人跳过的部分:
The swarm doesn’t just run fast. Run it right and it leaves something behind every time - a reusable skill, a sharper spec, a constraint that stops the next run from repeating today’s mistake.
群体不仅跑得快。运行得当,它每次都会留下一些东西——一个可复用的技能、一个更精确的规范、一个约束,防止下一次运行重复今天的错误。
The swarm that ran your task yesterday should be smarter than the one running it today.
昨天运行你的任务的群体,应该比今天运行它的那个更聪明。
Apr 23
Meet Kimi K2.6 Agent Swarm Highlights: Swarms, elevated - 300 parallel sub-agents × 4,000 steps per run (up from 100 / 1,500 in K2.5). Outputs are real files, not chat - one run delivers 100+ files, 100,000-word literature reviews, or 20,000-row datasets.
4月23日
遇见 Kimi K2.6 智能体集群亮点:集群,再升级——300 个并行子智能体 × 每次运行 4000 步(K2.5 为 100 / 1500)。输出的是真实文件,而非聊天内容——一次运行即可生成 100+ 个文件、10 万字的文献综述,或 2 万行的数据集。
That’s the loop. Kimi does the work and the learning. Opus 4.8 sits at one gate - the verify gate - and its only job is to stop garbage from getting saved as a skill. The engine learns. The closer keeps it honest.
这就是循环。 Kimi 负责工作与学习。Opus 4.8 守着一道门——验证门——它唯一的职责就是阻止垃圾内容被保存为技能。引擎在学习,把关人让它保持诚实。
Some people pick one model and marry it. Some chase the top benchmark line. Others wire up LangGraph and spend a weekend debugging a DAG.
有些人选了一个模型,就认准它了。有些人追逐顶级的基准线。另一些人则配置好 LangGraph,然后花一个周末调试一个 DAG。
The result is usually the same: a workflow that does the exact same thing on run #50 as it did on run #1.
结果通常都一样:一个工作流程在第50次运行时和第1次运行时所做的完全相同。
This is not that. This is the complete playbook for a swarm that compounds. 10 steps. Every prompt is copy-paste. Every number is verified.
这不是那个。这是一份完整的群聚复利行动手册。共10步。每个提示均可直接复制粘贴。每个数字都经过验证。
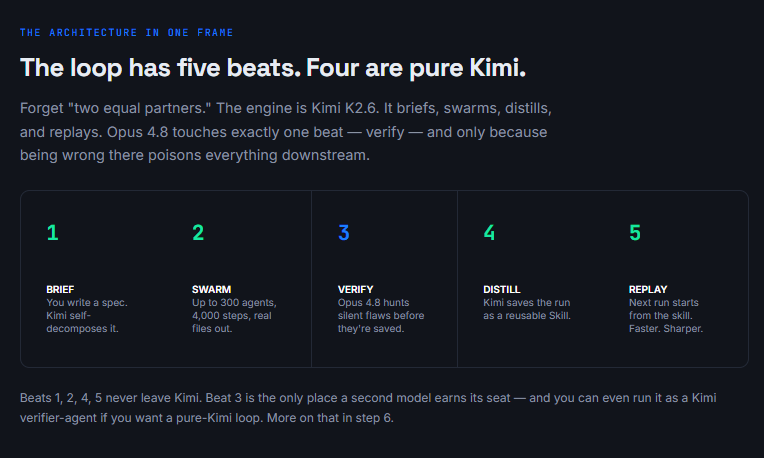
Part 1 - Build the loop once. Run it forever.
第一部分 - 构建一次循环,永久运行。
01. Write a spec, not a prompt
- 编写规范,而非提示词
When most people hear “300 agents” they fire off a one-liner -“research the fitness app market” - and expect brilliance. That’s the fastest way to burn credits and get junk.
当大多数人听到”300个智能体”时,他们会随口甩出一句——“研究一下健身应用市场”——然后期待出彩的结果。这是最快消耗积分并获得垃圾结果的方式。
A one-line prompt gives the swarm permission to decide everything, and it will decide wrong.
一行提示词就让群体获得了决定一切的权限,结果它必定会做出错误的决定。
Treat the swarm like a contractor, not a genie. A spec defines what to collect, what counts as valid, which sources are allowed, the exact output format, and what to do on conflict. Here’s the part most people skip: Kimi decides the decomposition itself.
把群体当作承包商,而不是精灵。规格说明定义了要收集什么、什么算有效、哪些来源被允许、确切的输出格式,以及发生冲突时如何处理。以下是大部分人忽略的部分:Kimi 自行决定分解方式。
You don’t build the agents like you would in CrewAI, you don’t wire the graph like LangGraph, you don’t define structure like AutoGen. You describe the goal - the swarm builds the org chart.
你不会像在CrewAI中那样构建代理,也不会像LangGraph那样连接图,更不会像AutoGen那样定义结构。你只需描述目标——集群会自动构建组织架构。
The spec is the single highest-leverage artifact in the whole loop, because in step 4 it becomes the seed of your reusable skill.
规范是整个循环中杠杆效应最高的单一制品,因为在步骤4中,它成为了你可复用技能的种子。
# PROJECT: [name]
GOAL: [one sentence — the deliverable, not the topic]
SCOPE: [what's in, what's explicitly out]
RULES: [validation — what counts as a verified row/finding]
SOURCES: [official posts, papers, primary only — no aggregators]
OUTPUT: [file type / count / naming / format details]
ON CONFLICT: flag the row, never resolve silently
STOP CONDITION: [when to halt and report instead of guessing]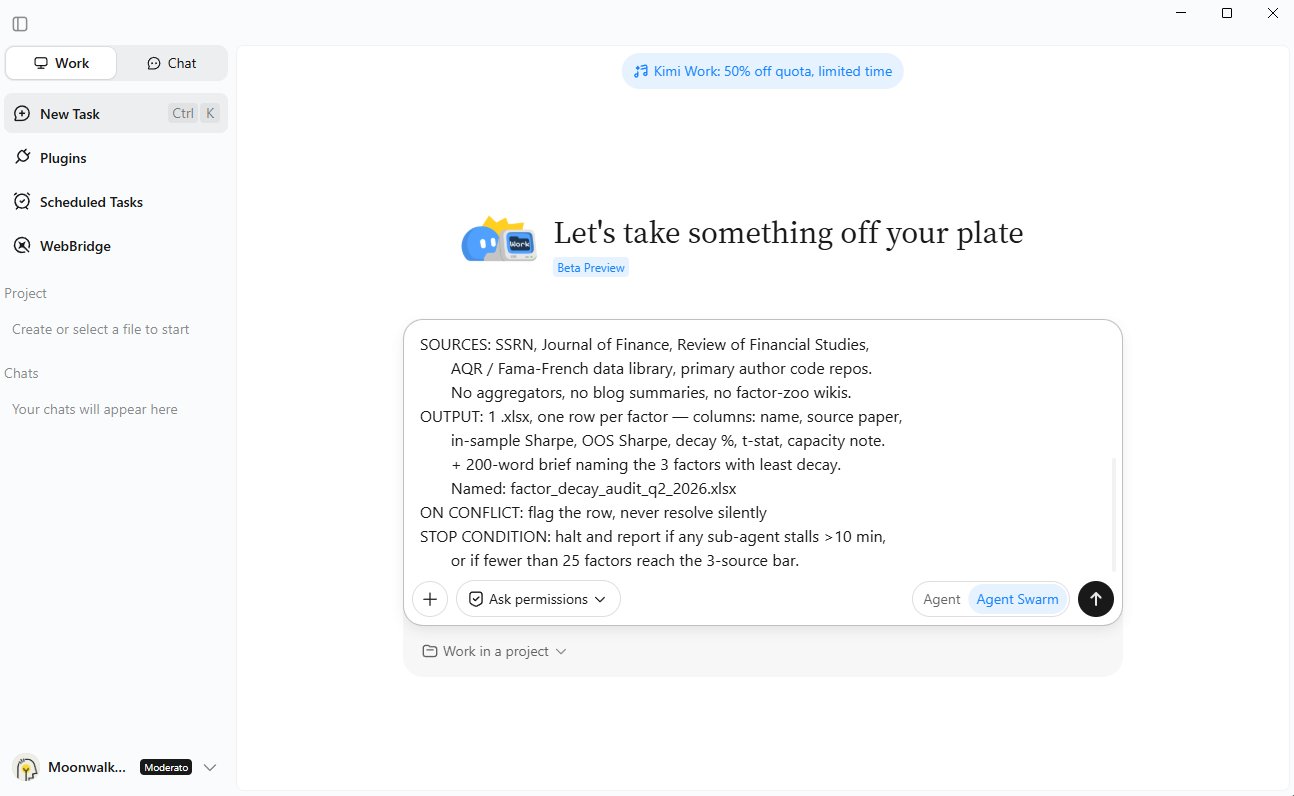
02. Read the decomposition plan before you spend a cent
02. 在花一分钱之前先阅读[分解计划]
This is the step first-timers skip, and it’s the most expensive one to skip.
这是新手最容易跳过的一步,也是跳过它代价最高的一步。
After you submit the spec, Kimi shows you the execution plan before it runs - how many sub-agents, what each handles, the dependency order, the step budget.
当你提交规格后,Kimi会展示执行计划——包含子智能体数量、各自负责的内容、依赖顺序、步骤预算。
Read it. A 200-agent swarm decomposed wrong costs real money and real hours. Checking the plan costs nothing. You’re looking for three things: does it understand the scope, is the agent count sane for the task size, and does the output plan match what you actually need.
阅读它。一个200个智能体的集群分解错误会浪费真实的金钱和时间,而检查计划则无需任何成本。你需要关注三件事:它是否理解任务范围,智能体数量对于任务规模是否合理,以及输出计划是否真正符合你的需求。
One detail worth knowing: the 4,000 steps is a total coordinated budget across the swarm, not 4,000 steps per agent. A 300-agent run averages ~13 steps each - short, specialized subtasks. That tells you whether your task fits the shape.
一个值得注意的细节:4000步是整个群体的总协调预算,而非每个代理单独走4000步。一次300个代理的运行平均每步约13步——简短、专业的子任务。这能让你判断自己的任务是否契合这种形态。
Show me the proposed decomposition before running:
- how many sub-agents, and what each one handles
- the dependency order (what blocks what)
- estimated step budget
- where the biggest quality-drop risk sits
Do NOT execute yet. Wait for my confirmation.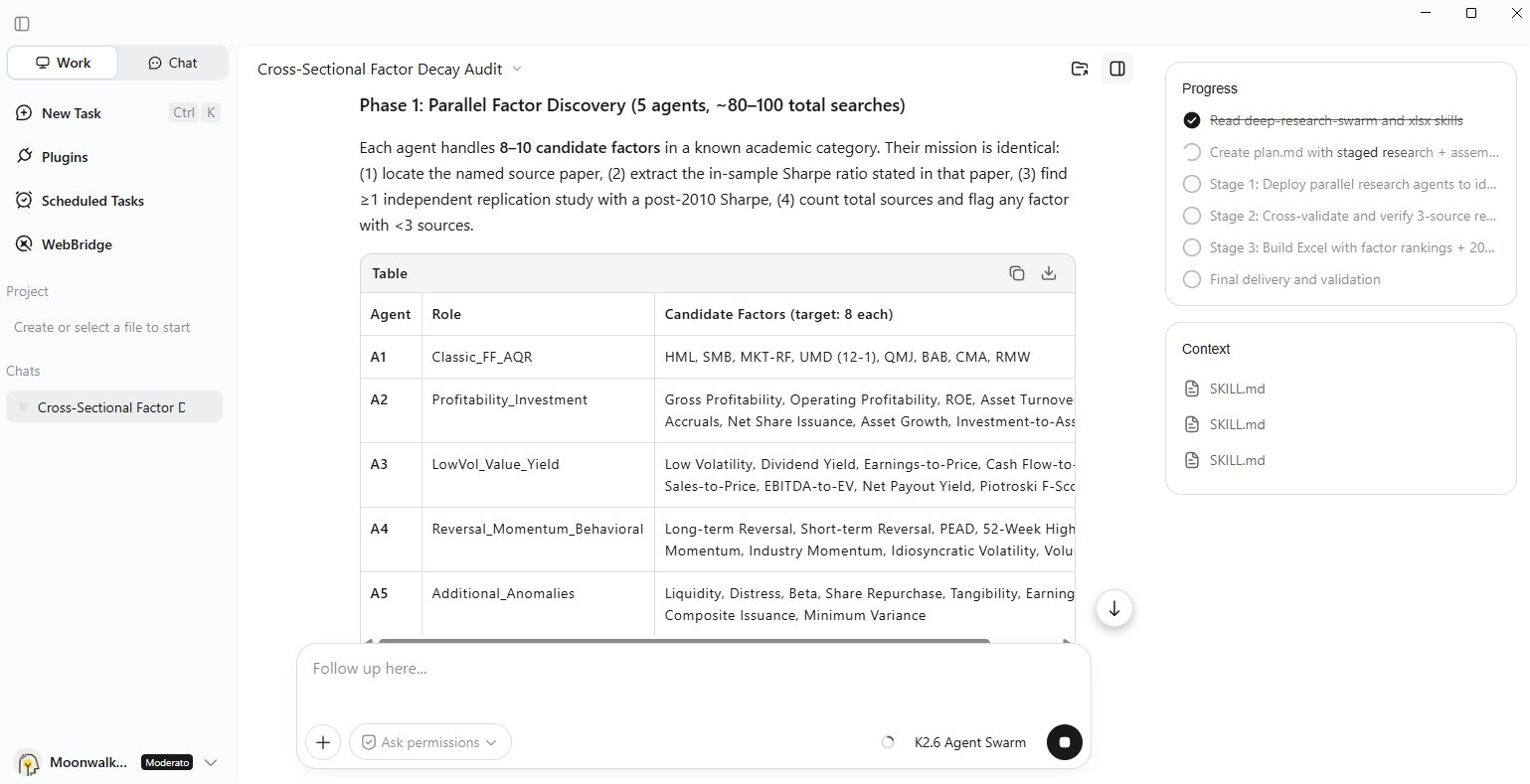
A one-line prompt is a wish. A spec is an order. The swarm executes orders.
一行提示是一个愿望。一份规格是一个命令。蜂群执行命令。
03. Let it be wasteful - that’s the point
- 让它浪费——这就是重点
Now you run it. Up to 300 sub-agents fire in parallel waves. The first wave handles fully independent subtasks.
现在你运行它。最多300个子代理以并行波次触发。第一波处理完全独立的子任务。
As results land, the orchestrator launches the next wave on whatever depended on them, until the dependency graph resolves.
随着结果的到达,编排器会启动下一波操作,处理所有依赖这些结果的任务,直到依赖关系图解析完成。
Each sub-agent works in its own bounded context window. That’s the structural trick: a single agent on a long task fills its window until it drowns and starts lossy summarization, and every reasoning step after that gets worse.
每个子代理都在其各自的有限上下文窗口中工作。这就是结构上的诀窍:单个代理在处理长任务时,会填满其窗口,直到它不堪重负并开始有损摘要,此后的每个推理步骤都会变得更糟。
The swarm gives each subtask its own scoped context, so only structured output flows back to the coordinator. That’s why it doesn’t collapse on tasks that break a single agent.
群体为每个子任务提供其独立的作用域上下文,因此只有结构化输出会流回协调器。这就是为什么它不会在那些会导致单个智能体失败的任务上崩溃。
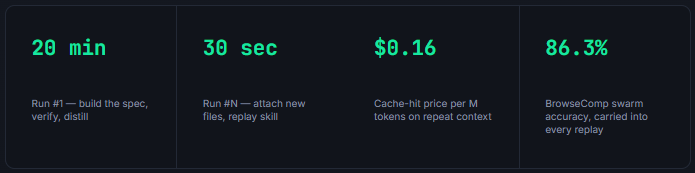
Because Kimi runs at $0.95/M in and $4.00/M out - with cache hits at $0.16 - you can afford to throw the first attempt away and run it again. Cheap volume changes what you’re willing to attempt.
由于 Kimi 的输入价格为每百万token 0.95 美元,输出价格为每百万token 4.00 美元——命中缓存时仅需 0.16 美元——你可以承担抛弃第一次尝试并重新运行的成本。低廉的批量价格改变了你愿意尝试的事情。
Execute the spec end to end.
Parallelize wherever the plan allows.
Report progress every 30 steps.
Flag any blocker immediately — do not work around it silently.
If a sub-agent stalls >10 min, reassign or report.
Merge everything into the OUTPUT defined in the spec.
04. Demand real files, not a chat answer
- 要求真实文件,而非聊天答案
The output of a swarm is not text in a window. It’s structured deliverables that go straight into your work - and this is the part most articles miss.
群组的输出并不是窗口中的文本,而是可以直接融入你工作的结构化成果——这正是大多数文章忽略的部分。
One run lands PDFs, spreadsheets, datasets, slide decks, and working code, all from a single launch, because Kimi emits those formats natively.
一次运行就能获取PDF、电子表格、数据集、演示文稿和可运行代码,全部从单一启动中实现,因为Kimi原生生成这些格式。
So lead the spec with the output, always.
因此,始终用输出来引导规范。
“A comprehensive report” gives agents permission to stop early. “A 40-page PDF + one CSV with 20,000 rows + 14 export-ready PNG charts” gives them a quality target to hit.
“一份全面的报告”让智能体可以提前停止。“一份40页的PDF + 一个包含20,000行数据的CSV + 14张可直接导出的PNG图表”则为其提供了明确的质量目标。
Specificity at the output level is the difference.
输出层的特异性就是差异所在。
OUTPUT: [file type] / [count] / [naming] / [format detail]
# strong examples:
OUTPUT: 1 .xlsx, one row per model, + 200-word brief
OUTPUT: 30 HTML files, one per store, named by business
OUTPUT: 40-page PDF + 20,000-row CSV + 14 PNG charts
05. Point the honest model at the output and ask what’s wrong
05. 将诚实模型指向输出,并询问哪里出了问题
Here’s the one beat that isn’t Kimi. The swarm’s known flaw: unless you explicitly demand verification, it produces confident, under-cited claims, and independent sub-agents sometimes contradict each other. “Looks done” and “is correct” are different planets.
这是唯一一个不像 Kimi 的弱点:群组的已知缺陷在于,除非你明确要求验证,否则它会给出自信但引用不足的说法,而独立的子代理有时会相互矛盾。“看起来完成了”和“确实正确”是两码事。
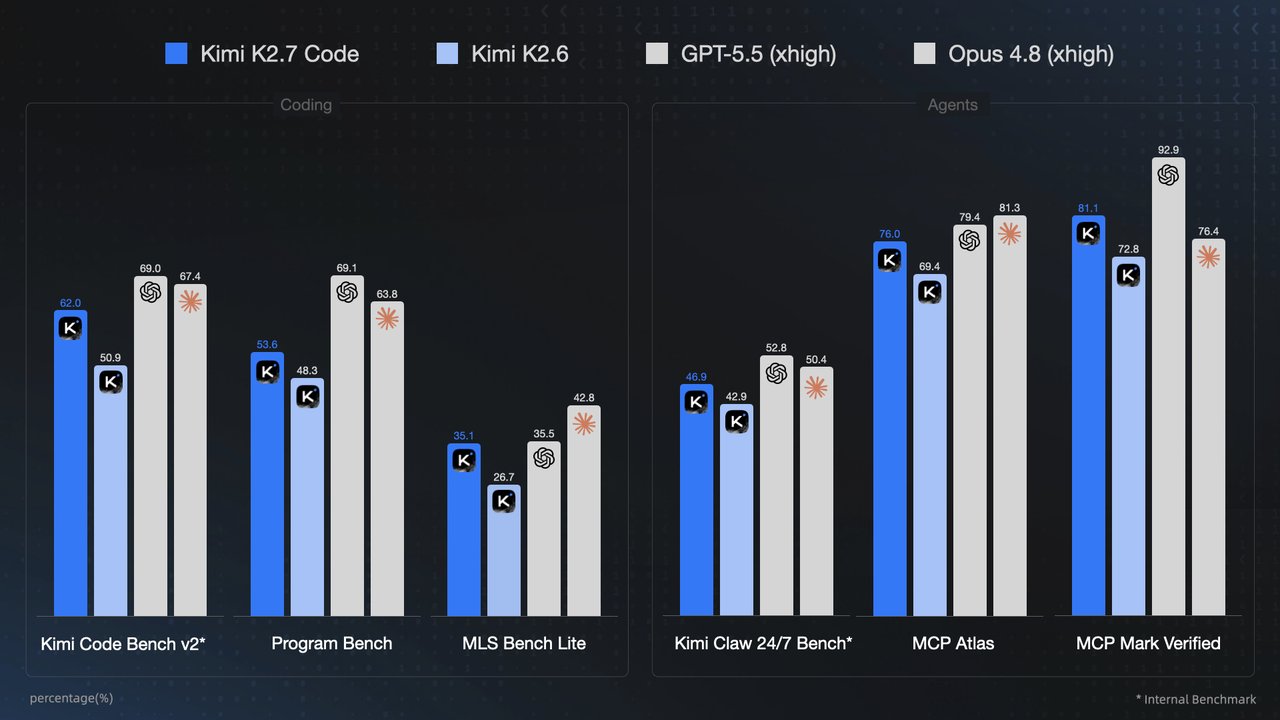
Opus 4.8 is built for exactly this gate. Anthropic reports it’s roughly 4x less likely than 4.7 to let a flaw in its own code pass unremarked, and it’s the first Claude to score 0% on uncritically reporting flawed results.
Opus 4.8 正是为此而构建的。Anthropic 报告称,相比 4.7,它发现自己代码缺陷而不被发现的可能性大约降低 4 倍,并且它是第一个在未加批判地报告有缺陷结果的问题上得分为 0% 的 Claude 版本。
Its only job here is to refute, not to praise. You’re not paying premium tokens to generate - you’re paying them to catch the silent flaw before step 4 saves it into a skill forever.
它在这里的唯一工作是反驳,而不是赞扬。你支付的并非高级代币来生成——你支付它们是为了在第四步将其永久化为技能之前,捕捉到那个无声的缺陷。
Cheap volume is only a superpower when something trustworthy is checking the work. Keep the verify gate.
廉价的数量只有在有可信的东西检查工作时才是一种超能力。保持验证关卡。
06. Save the whole workflow as a Skill
- 将整个工作流保存为技能
This is the beat that makes the loop self-improving. After a run you’ll repeat, tell Kimi to capture the entire workflow as a reusable Skill - input format, agent steps, output format.
这就是让循环自我优化的节拍。运行一次后,你需要重复操作,告诉Kimi把整个工作流程捕捉为一个可复用的Skill——包括输入格式、智能体步骤和输出格式。
The first run takes 20 minutes. Every run after it takes 30 seconds.
第一次运行需要20分钟。之后的每次运行需要30秒。
That’s the honest version of “self-learning.” The model isn’t retraining its weights between your runs.
那就是“自我学习”的诚实版本。模型不会在每次运行之间重新训练其权重。
The system around it is getting smarter - your skill library grows with every project, and every future swarm applies those skills automatically.
其周围的系统正在变得更智能——你的技能库随着每个项目而增长,未来的每一个群体都会自动应用这些技能。
A competitor can’t copy that library in a week. It’s built from months of your real runs.
竞争对手不可能在一周内复制那个库,它是你数月真实运行积累而成的。
Save this entire workflow as a reusable Skill: "[name]"
Capture:
- input format (what files / spec shape it expects)
- the agent steps that worked
- the output format and naming convention
- the validation rules from the spec
Next time I run this, I attach new files and get the same shape.
07. Feed your own documents in as swarm knowledge
- 将自己的文档作为群体知识输入
Skills capture process. Document-to-Skill captures domain. Upload your best work - a closed-deal proposal, a polished report, a deck - and Kimi captures its structural and stylistic fingerprint as a skill every future swarm applies automatically.
技能捕获流程。Document-to-Skill 捕获领域。上传你最好的作品——一份成交的提案、一份精炼的报告、一个演示文稿——Kimi 便会提取其结构和风格特征,形成一项技能,未来的每一个 swarm 都将自动应用这项技能。
Here’s where it compounds: every PDF, transcript, or spreadsheet you feed in becomes context that all 300 parallel agents can ground against, instead of falling back on general training data.
关键在于,每份你输入的PDF、转录稿或电子表格都会成为上下文,让所有300个并行代理得以据此进行推理,而不是依赖通用训练数据。
The more you feed it, the more accurate every subsequent run becomes. Reports stop reading like generic AI and start reading like your work.
你喂给它的数据越多,后续每次运行的结果就越准确。报告读起来不再像泛泛的AI生成内容,而更像是你的真实成果。
Capture this document as a reusable skill. Identify what makes it work:
- structure and section order
- tone and voice register
- depth of analysis per section
- the writing rhythm and formatting decisions
Save it as "[name]". Then produce a new document on [different topic]
using the captured skill — match the quality bar, not the content.
08. Turn the verify feedback into a permanent rule
08. 将验证反馈转化为永久规则
Step 5 catches a flaw once. Step 8 makes sure the swarm never makes it again. Take Opus’s fix list and don’t just patch the output - bake the lesson into a project-level constraints file Kimi reads automatically at the start of every session.
第5步抓住了一次缺陷。第8步确保群体不再犯同样的错误。拿Opus的修复清单,不要只修补输出——将经验教训融入一个项目级别的约束文件中,Kimi会在每次会话开始时自动读取该文件。
This is the loop learning from its own failures. The drift that Opus flagged on run #1 becomes a hard rule on run #2.
这是从自身失败中学习的循环。Opus 在 run #1 中标记的漂移在 run #2 中变成了硬性规则。
Over a few projects, your constraints file turns into living documentation that enforces itself - and the verify gate has less and less to catch each time.
经过几个项目,你的约束文件变成了自行执行的活文档 - 而验证关卡每次能捕捉到的问题越来越少。
# CONSTRAINTS.md — loaded automatically
- every claimed figure must trace to a primary source or be flagged
- no silent conflict resolution — surface contradictions
- [rule distilled from last run's Opus feedback]
- [the mistake you never want repeated]
Scope-lock: do not touch anything outside the spec's SCOPE block.09. Replay the skill on new inputs - watch the cost collapse
- 对新输入重放该技能 - 观察成本骤降
Now the payoff. Run #2 doesn’t start from zero. It starts from the skill, the swarm knowledge, and the constraints file you built in steps 6–8.
现在到了收获的时刻。第二次运行并非从零开始,而是始于你在步骤6–8中构建的技能、群体知识和约束文件。
Same workflow, new files, a fraction of the setup.
相同的工作流程,新的文件,极少设置。
This is where “compounding” stops being a buzzword and shows up on the invoice. The first competitive-monitoring run takes a full spec and a verify pass.
这正是“复合”不再只是一个流行词,而是真真切切体现在发票上的时刻。首次竞争监控运行需要完整的规范说明和一次验证通过。
The fourth one is a 30-second prompt against the saved skill, and the output is sharper because it inherits every fix from the runs before it.
第四个是一个针对已保存技能的30秒提示,其输出更加清晰,因为它继承了之前所有运行的修复。
Run the saved skill "[name]" on these new inputs.
Apply CONSTRAINTS.md. Use the captured output format.
[attach new files]
Report only deviations from the skill's expected shape.20 minutes on run one. 30 seconds on run fifty. That gap is the whole reason to build a loop instead of a prompt.
运行1耗时20分钟。运行50仅需30秒。这一差距正是构建循环而非提示的全部理由。
10. Promote the loop to a background agent
10. 将循环提升为后台代理
The final move: once a loop is stable and skill-backed, you stop launching it by hand.
最后一步:一旦循环稳定且技能已就绪,就停止手动启动它。
Point Kimi at the trigger - a schedule, a new file drop, a competitor’s pricing page - and let it run the whole loop proactively, surfacing only the deliverable and the deviations.
让Kimi瞄准触发点——一个日程、一个新文件的出现、或竞争者的定价页面——然后让它主动跑完整个循环,只呈现交付结果和偏差之处。
Competitive monitoring is the clean example.
竞争性监控是一个清晰的例子。
Run #1 you build and verify by hand. By the time it’s a background agent, it’s checking every competitor in parallel weekly and dropping a brief in your inbox at zero marginal time cost.
运行#1,你手动构建并验证。当它成为后台代理时,它会每周并行检查每个竞争对手,并以零边际时间成本将简报投递到你的收件箱。
The only human left in the loop is the question you set and the decision you make on the answer.
循环中唯一剩下的人类干预,就是你设置的问题以及根据答案所做的决定。
Run skill "[name]" on a weekly schedule.
Trigger: [schedule / new file / monitored URL]
On each run: execute the swarm, apply CONSTRAINTS.md,
verify, then deliver the OUTPUT + a diff vs last run.
Only ping me if a deviation crosses [threshold].Conclusion:
结论:
While the closed labs keep shipping one smarter chatbot at a time, an open model is running 300 agents in parallel - and getting smarter at the system level with every run you give it.
封闭实验室不断推出一个又一个更智能的聊天机器人,而一个开放模型却在并行运行着300个智能体——并且在你每次运行时,它在系统层面变得越来越智能。
We’ve seen this exact fingerprint once already. An open release reframes what the closed frontier thought it owned, and the whole field recalibrates overnight. It happened with DeepSeek.
我们之前已经见过完全相同的模式。一次开放发布重新定义了封闭前沿曾经视为己有的领域,整个领域在一夜之间重新校准。DeepSeek 就是如此。
A self-learning swarm on an open-weight model has the same shape.
在开放权重模型上的自学习集群具有相同的形态。
The builders still arguing about which model “won” are answering a question that stopped mattering.
那些仍在争论哪个模型“赢了”的构建者们,正在回答一个已经不再重要的问题。
The question now isn’t which model is smartest. It’s how many you can run at once, who’s checking their work, and whether your setup is sharper today than it was yesterday.
现在的问题不是哪个模型最聪明。而是你能同时运行多少个,谁在检查它们的工作,以及你的设置今天是否比昨天更出色。
Most people will read this and keep using Kimi as a chatbox. A few will build the loop this week. The first run takes 20 minutes. Every run after that is leverage you own.
大多数人会读到这段话,然后继续把Kimi当成一个聊天框来用。少数人会在本周构建起这个循环。第一次运行需要20分钟。之后的每一次运行都是你自己的杠杆。
Build it. Verify it. Distill it. Then watch it get cheaper and sharper every single time you run it.
构建它。验证它。提炼它。然后每一次运行它,你都会看到它变得更廉价、更锐利。